Beating the Heat : How We Cooled Down Cassandra’s Hot Partitions to scale

In the fast-paced world of fantasy sports, My11Circle stands out by offering sports fans the thrill of building dream teams and competing for real rewards. But behind the scenes, it's the robust backend technology that ensures a seamless experience, especially during high-stakes events like the IPL and World Cup.
With millions of users creating teams and joining contests in a single match, keeping leaderboards accurate and fast is no small task. To handle this massive scale, we use Apache Cassandra for storing leaderboard data. However, as contests grew bigger, we faced performance issues that challenged our scaling strategies.
The Fantasy Sports Technical Challenge :
Fantasy sports platforms like My11Circle face unique technical challenges:
- Massive Data Volume: Contests can include millions of participants.
- Prompt Availability: Users expect to see final leaderboards immediately after matches conclude.
- Resource Efficiency: Optimizing database utilization to control infrastructure costs.
- Scaling Headroom: Accommodating growing contest sizes without architecture overhauls.
These requirements demand a robust database solution that can handle the persistence and retrieval of large-scale leaderboard data.
Our Leaderboard Architecture :
At My11Circle, we use a two-tier approach for our leaderboard system:
- Redis: Serves real-time leaderboard updates during active matches.
- Apache Cassandra: Persists final leaderboard data once matches are completed.
This blog focuses on the Cassandra persistence layer, which faced scaling challenges as our user base grew.
Understanding Cassandra's Data Architecture :
To appreciate the optimization we implemented, it's important to understand how Apache Cassandra organizes and processes data.
Cassandra's Core Concepts :
Primary Key: Unlike traditional relational databases where a primary key simply identifies a row, in Cassandra, the primary key serves dual purposes:
- Uniquely identifies a row.
- Determines data distribution across the cluster.
The Partition Key: This is the first component of the primary key that determines which node in the cluster will store the data. It's crucial for performance and scalability.
Clustering Key: Additional columns in the primary key that determine the sorting order within a partition.
What is a Partition in Cassandra ?
A partition is a fundamental unit of data storage in Cassandra, containing rows that share the same partition key. Understanding partitions is essential because:
- Partitions determine how data is distributed across nodes
- They directly impact write performance
- Properly sized partitions ensure balanced workload distribution
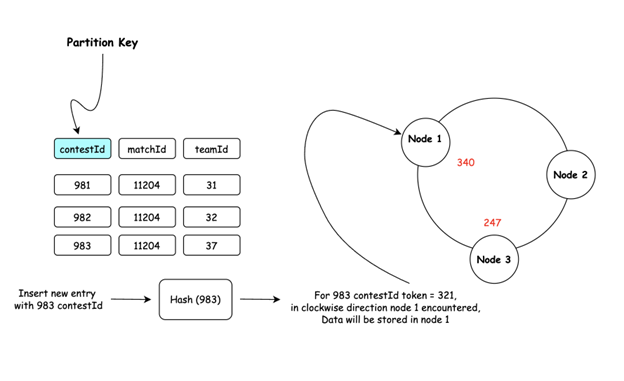
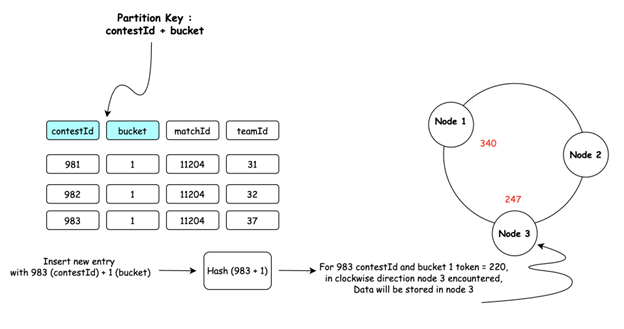
How Data is Partitioned :
- Partition Key Selection: The partition key (single column or composite) determines data placement.
- Hashing Process: Cassandra applies a hash function to the partition key to generate a token.
- Token Assignment: This token corresponds to a value on the ring. Each node in the cluster is responsible for a range of tokens.
- Data Distribution: It takes the token value and walks clockwise on the ring and whichever node it meets first, that is the node the data is stored in. This token-based distribution ensures data is evenly spread across the cluster.
The Challenge : Hot Partitions at Scale
My11Circle's Leaderboard System :
At My11Circle, we run multiple contests within each match. These contests vary in size and prize pools:
- Regular contests: Typically lakhs of participants.
- Mega contests: Can reach 20 million participants during Major sport events.
Each contest has its own leaderboard, which is updated in Redis during live matches. Once a match concludes, we persist the final leaderboard in Cassandra through a Spark-based service.
Our Original Table Design :
In a match, each contest is uniquely identified by a contest_id. When users join a contest, they create teams (each with a team_id), and based on performance, each team receives a rank in the final standings.
-
contest_idserved as the partition key, determining how data was distributed across the Cassandra cluster - rank and
team_idwere clustering keys, organizing data within each partition
This design seemed logical at first - grouping all teams from the same contest together. However, it created a critical scaling limitation: all data for a single contest was stored in one partition, regardless of size. For mega contests with millions of participants, this resulted in extremely large partitions that overwhelmed individual Cassandra nodes.
The Problem Emerges :
As our platform grew, we began experiencing performance issues:
Observed Metrics and Bottlenecks
- Uneven Resource Utilization: During high-traffic matches, some nodes were overworked while others remained idle.
- Node CPU Imbalance: We observed significantly higher CPU utilization on specific nodes in our Cassandra cluster, reaching 80% CPU while others remained at 30-40% during the same workload period.
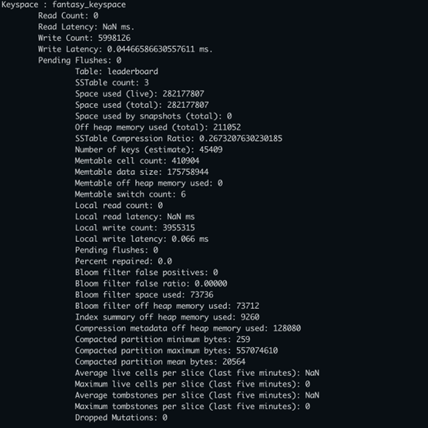
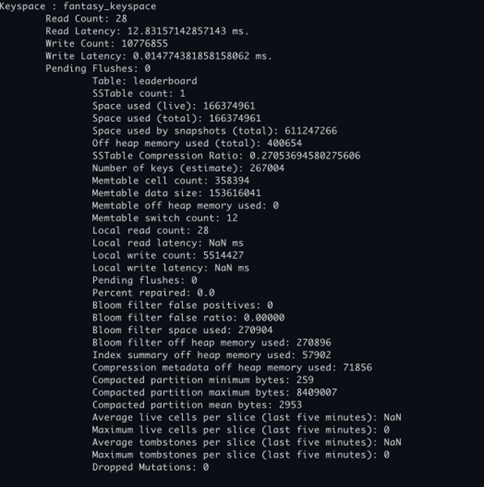
- Warning Logs: Examined server logs on impacted Cassandra node. WARN [CompactionExecutor] Writing large partition fantasy_keyspace/leaderboard:127937062 (438.982MiB)
- Partition Size Explosion: Mega contests created partitions exceeding 500-800 MB, far beyond Cassandra's recommended 100 MB limit.
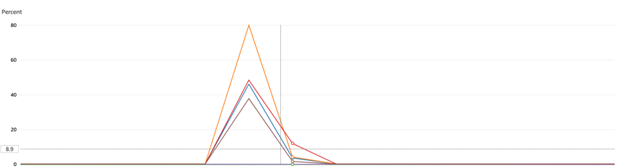
- Data persistence time : Data persistence time increased as load increased.
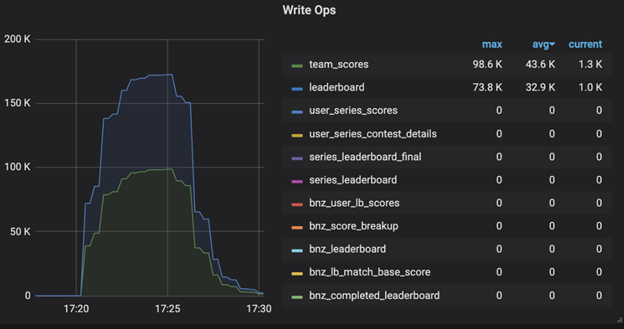
Diagnosis : Hot Partitions
The root cause became clear: our design was creating “hot partitions” , partitions that received disproportionately high write traffic compared to others. The collected metrics served as evidence of the issue.
Why Partition Size Matters in Cassandra :
Oversized partitions create several critical performance issues in Cassandra:
1. Write Performance Degradation
Large partitions require more resources to process updates, causing increased latency during leaderboard persistence.
2. Memory Pressure
Oversized partitions consume disproportionate amounts of memory, triggering more frequent garbage collection and affecting overall system performance.
3. Compaction Overhead
Cassandra's compaction process struggles with large partitions, consuming excessive resources and potentially falling behind during peak periods.
4. Node Imbalance
Hot partitions create uneven workload distribution, making some nodes work significantly harder than others in the cluster.
5. Scalability Ceiling
As contest sizes grew with each tournament, we faced an architectural ceiling that couldn't be efficiently solved through vertical scaling.
Reducing partition size was essential to create a stable, predictable, and cost-efficient database layer for our growing platform.
The Solution : Bucketization for Better Distribution
After analyzing our options, we implemented a distribution technique called "bucketization" to evenly spread data across partitions.
Finding the Optimal Bucket Key :
We needed to identify a bucketization value that would:
- Be readily available during query execution
- Ensure uniform data distribution
- Require minimal application modifications
Since users must create teams to participate in contests, and team rankings are already available pre-query, we leveraged these rankings as our bucket key for optimal data distribution.
Bucketization Implementation :
Rather than relying solely on contest_id as the partition key, we enhanced our approach by incorporating a calculated bucket value:
Bucket Formula : bucket = (rank / K) + 1
Through extensive load testing, we determined K = 10,000 provides ideal performance:
- Teams ranked 1-9,999 are assigned to bucket 1
- Teams ranked 10,000-19,999 are assigned to bucket 2
- This pattern continues for all rankings
The K = 10,000 value resulted in consistently sized 5-20 MB partitions, striking the perfect balance for our query performance and storage requirements.
New Table Schemas :
Note the composite partition key (contest_id, bucket), which spreads data across multiple partitions.
Key Performance Improvements :
1. Even Resource Distribution : CPU and memory usage became balanced across nodes.
2. Enhanced Scalability : The system can now handle larger contests without expensive hardware upgrades. This has enabled us to scale horizontally, helping us save approximately 50% in costs during peak tournament seasons.
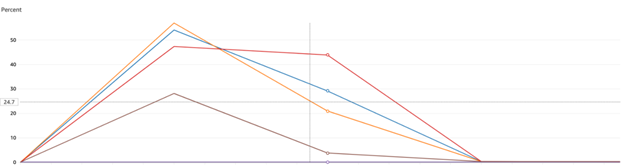
3. Eliminated Hot Partitions : No more partition size warnings or performance bottlenecks.
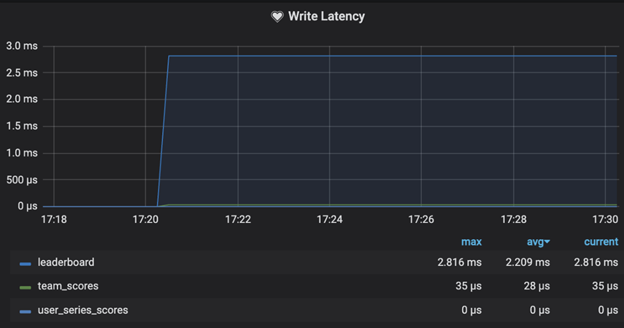
4. Write Efficiency : The 99% reduction in write latency ensures faster updates.
5. Faster Leaderboard Availability : The 33% improvement in data persistence time ensures the final leaderboard is visible to users sooner, enhancing their experience.
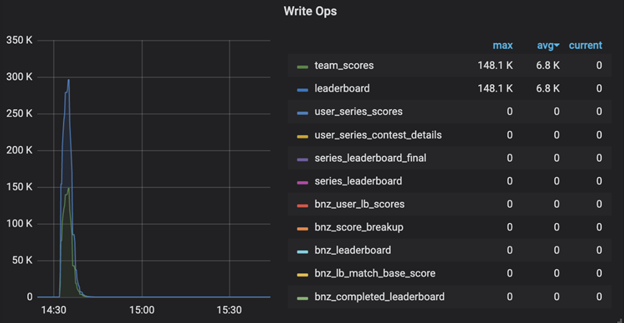
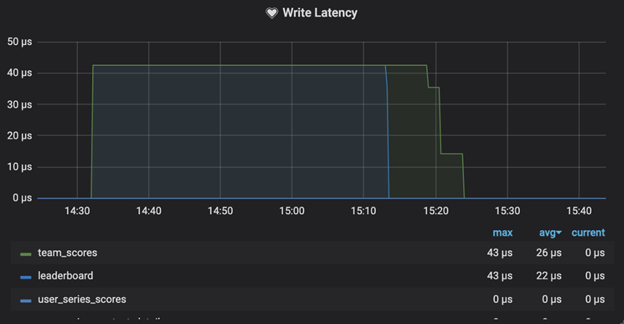
The Impact: Faster, Leaner and More Scalable :
The results were dramatic :
Implementation Strategy : Phased Rollout
To minimize the risk, we implemented a phased rollout strategy:
- New Table Creation :
- We created the new leaderboard table in the existing Cassandra cluster.
- ZooKeeper-Based Configuration :
- We used ZooKeeper to manage which matches/series would use the new table structure.
- This allowed for gradual transition on a match-by-match basis.
- Common configuration was deployed so multiple services could read from the same path.
- Dual-Write/Read Logic :
- During settlement, our Spark service (Thor) would check if the matchId/seriesId was in the ZooKeeper config
- If included, data would be persisted to the new leaderboard table.
- For reads, our Leaderboard Service would check the same ZooKeeper config to determine which table to query for a particular matchId.
- Progressive Rollout :
- Started with small-scale matches first.
- Gradually expanded to larger matches as confidence grew.
- Monitored performance at each stage.
This approach allowed us to validate improvements in a controlled manner before full deployment.
Lessons Learned :
This optimization journey taught us several valuable lessons :
- Data modeling is crucial : In distributed databases, how you structure your data is as important as the infrastructure itself.
- Anticipate growth : Design for future scale, not just current needs.
- Monitor partition sizes : Regular monitoring helps catch issues before they become critical
- Simple solutions can have big impacts : Sometimes a small change in data structure yields tremendous performance gains.
- Phased rollouts reduce risk : Gradually implementing changes allows for validation without widespread impact.
Conclusion :
A small but strategic change adding a simple bucket for partitioning made a huge impact on our platform's performance and scalability. This change helped us avoid expensive vertical scaling and ensured a smoother, faster experience for millions of users during high-stakes events.
The improvement didn't just enhance technical metrics; it directly impacted user experience by ensuring faster contest leaderboard generation and more reliable service. As we continue to grow, this optimization will enable us to scale efficiently while maintaining the performance our users expect.
It's a great reminder that sometimes, the simplest solutions bring the biggest results.
About author :
Mayank Sisode is working as a Software Engineer at Games24x7, with around 4.5 years of experience in backend development. He enjoys solving challenging problems and loves working on distributed systems that handle scale and complexity.
References :
- https://www.instaclustr.com/blog/cassandra-data-partitioning/
- https://docs.datastax.com/en/cassandra-oss/3.0/cassandra/cassandraAbout.html
Explore More
Discover the latest insights from the world of Games24x7


